R&D scientists today are surrounded by data. Rheology measurements, stability studies, surface tension profiles, foaming behavior, and countless formulation variables accumulate with every project. Yet most formulation workflows remain fragmented, static, and heavily dependent on trial-and-error. Each experiment adds knowledge, but that knowledge rarely compounds in a meaningful, scalable way.
Data lives in separate files. Institutional knowledge lives in the heads of experienced formulators. When those formulators move on, their accumulated understanding goes with them. New projects often start from scratch, even when relevant experiments have been run before. The organization generates data continuously but only learns from it intermittently.
Machine learning has generated significant interest in formulation R&D, but for many scientists a gap remains between the promise and the practice. Discussions focus on what models can predict, not on how they fit into the day-to-day work of designing and testing formulations. The answer lies in treating deep learning not as a separate tool to consult occasionally, but as an integral component of the workflow itself: a platform that continuously ingests experimental data, identifies patterns, and improves its predictions with every iteration.
The Traditional Workflow and Its Limitations
The standard formulation development process follows a familiar pattern. Teams define performance targets and constraints. They design experiments, often using DOE principles, to explore how formulation variables affect outcomes. They run those experiments, collect data, analyze results, and iterate based on findings. The cycle repeats until an acceptable formulation is found.
This approach works, but it has structural limitations that become more apparent as formulation complexity increases.
Each project essentially starts fresh. A team working on a new product line may have access to data from previous projects, but that data typically sits in archived files rather than actively informing current decisions. The connection between past experiments and present work depends on individual memory and informal knowledge transfer.
Knowledge accumulation is fragile. An experienced formulator develops intuitions about which ingredient combinations work and which do not, which concentration ranges are promising, and which processing conditions matter most. These intuitions are valuable but difficult to transfer. They exist in one person's head, not in a system that persists across the organization.
There is no mechanism for learning across projects or time. The organization does not become systematically smarter with each experiment. Running a hundred experiments does not make the hundred-and-first experiment more efficient unless someone remembers the relevant results and applies them correctly. Scaling R&D capacity requires hiring more people rather than building smarter systems.
Trial-and-error remains dominant despite decades of accumulated experience. The fundamental approach has not changed: propose formulations, test them, learn from failures, iterate. The tools have improved, but the workflow structure has not.
A Continuously Learning Workflow
Deep learning platforms offer a different model. Instead of treating experiments as isolated data points, the platform treats each experiment as a contribution to a growing foundation of understanding. The workflow becomes a loop rather than a line: data flows into the platform, the platform learns, predictions improve, and those predictions guide the next round of experiments.
Over time, this evolves into something more powerful than a prediction tool. It becomes a chemical intelligence platform that understands your formulation space, learns your specific chemistry, and grows with your data. Instead of restarting with every new project, scientists build on an expanding foundation of insight that encompasses everything the organization has learned.
The platform is not a one-time resource you consult and set aside. It is a persistent learning system that becomes more valuable the more it is used. Every experiment feeds back into the system. Every data point refines the model's understanding of how ingredients behave and interact.
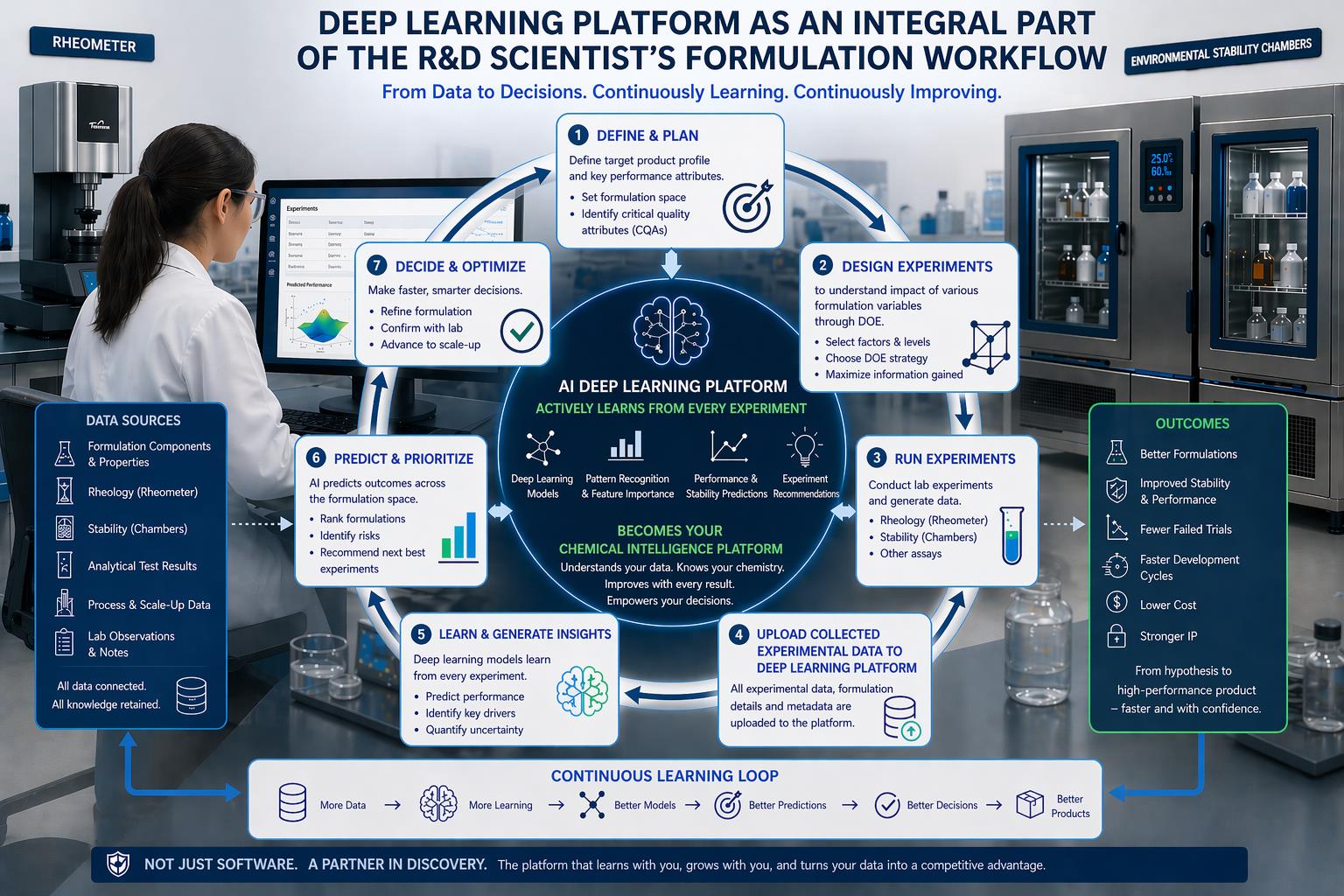
The Intelligent Formulation Workflow Loop
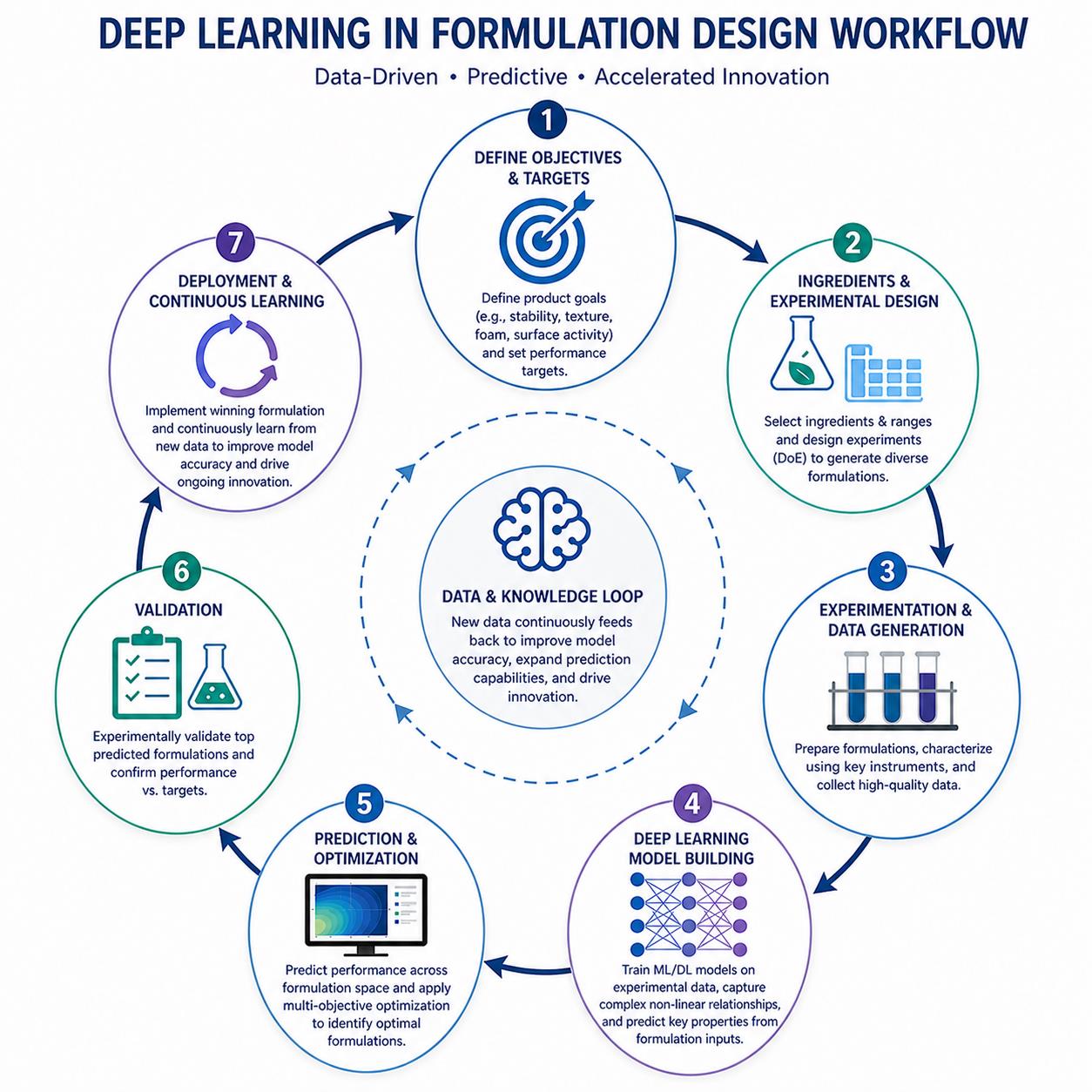
Integrating deep learning into formulation development creates a seven-stage cycle with the AI platform at its center. Each stage connects to the others, forming a continuous loop that accelerates with every iteration.
Stage 1: Define and Plan
Every formulation project begins by defining the target product profile. What performance attributes matter? What are the acceptable ranges for viscosity, stability, surface tension, and foaming behavior? What constraints apply, whether regulatory, cost, or ingredient availability?
Stage 2: Design Experiments
With targets defined, the next step is designing experiments to explore how formulation variables affect outcomes. DOE principles guide this process: selecting factors and levels, choosing an appropriate experimental strategy, and maximizing the information gained from each experiment.
As the learning loop continues, this stage becomes more efficient. With each iteration, the model's predictions become more reliable, meaning fewer exploratory experiments are needed to map the formulation space. Early DOE studies may require broad coverage; later studies can be more targeted.
FastFormulator's platform comes pre-equipped with thousands of well-designed experiments, specifically captured to build a knowledge base on how formulation ingredients and variables affect physicochemical outcomes.
Stage 3: Run Experiments
Laboratory work generates the data that feeds the entire system. Rheology measurements from rheometers, stability testing in environmental chambers, surface tension measurements, and foaming assays all produce structured data about how formulations behave.
Stage 4: Upload Experimental Data
All experimental data and formulation details are uploaded and integrated to the platform in a simple excel format. This includes formulation components and their concentrations, rheology data across shear rates, stability results at various time points and conditions, surface tension measurements, and foaming data.
Stage 5: Learn and Generate Insights
This is where continuous learning occurs. Deep learning models process the uploaded data and refine their understanding of how formulation composition relates to physicochemical properties.
The platform predicts key properties that govern formulation performance:
- Viscosity and rheology flow curves. How the formulation flows under different shear conditions, which determines behavior during processing, dispensing, and application.
- Colloidal stability. Whether the formulation will remain homogeneous over time or undergo phase separation, sedimentation, or other degradation.
- Surface tension. How quickly and effectively the formulation wets surfaces, which affects cleaning performance, spreading, and interfacial behavior.
- Foam generation and longevity. How much foam forms under agitation and how long it persists, which matters for both positive foaming (cleaning products) and foam control (industrial fluids).
Each new data point refines the model's understanding. The model identifies patterns and relationships that may not be obvious to human intuition, connections between ingredient combinations and outcomes that would be difficult to extract from scattered experimental records.
Stage 6: Predict and Prioritize
With an updated model, the platform can predict outcomes across the formulation space, including regions that have not been experimentally tested. This enables a different kind of decision-making.
The platform can rank formulations by predicted performance against target properties. It can recommend which experiments to run next, prioritizing formulations that are predicted to meet targets or that would provide the most informative data. It can highlight regions of composition space worth exploring that human intuition might overlook.
Predictions guide experimental priorities, reducing blind trial-and-error. Instead of testing formulations sequentially based on intuition alone, teams can focus experimental effort where it is most likely to yield results.
Stage 7: Decide and Optimize
Armed with predictions, formulators make faster, smarter decisions. They refine formulations based on model guidance, confirm promising candidates with targeted lab experiments, and advance validated formulations toward scale-up.
The loop closes here: experimental results from validation studies feed back into the platform, and the cycle continues. Each iteration through the loop adds to the foundation of knowledge, making the next iteration more efficient.
The Continuous Learning Loop and Diminishing Data Requirements
The workflow described above is not a one-time process. It is a continuous loop: more data leads to more learning, which produces better models that enable better predictions, drive better decisions, and ultimately create better products faster.
A critical feature of this loop is that as it continues, the model requires decreasingly less data to make accurate predictions in new regions of formulation space.
Early in the loop, the model needs broad coverage. It must see how different ingredient classes behave across concentration ranges and under varying conditions. It must observe pairwise interactions between surfactants and polymers, between emulsifiers and oils, between active ingredients and the surrounding matrix. Building this foundational understanding requires systematic data generation.
As understanding builds, fewer experiments are needed to extend into new territory. The model learns transferable patterns about how ingredient classes behave and interact. When it encounters a new surfactant, it can draw on what it has learned about surfactants generally. When asked to predict stability for a novel combination, it applies patterns learned from thousands of prior stability observations.
This means the platform becomes more valuable over time, not less. It does not restart for each new product or project. Institutional knowledge is captured in the model itself, accessible to any team member who uses the platform. New scientists joining the organization benefit immediately from the accumulated learning of every experiment that came before.
Traditional R&D treats each project as separate. This approach treats every experiment as a contribution to an expanding foundation of insight that makes all future work more efficient.
Building This Capability from Scratch
In theory, any organization could build a continuous learning formulation platform. In practice, doing so requires substantial upfront investment that most formulation teams are not positioned to make.
Systematic DOE design. Building a foundational model requires more than just accumulating experimental data. It requires carefully structured studies designed to teach the model how ingredients behave. This means starting with single-component measurements across varying conditions to establish baseline behavior. It means systematically generating pairwise combinations to capture interaction effects. It means progressing to multi-component mixtures that reflect real formulation complexity. The wrong DOE structure produces data that does not generalize. Running thousands of experiments without systematic design yields a model that memorizes specific formulations but cannot predict new ones.
Architecture design. Building neural network architectures that encode chemical structure and learn composition-dependent interactions requires specialized machine learning expertise. The architecture must represent molecular structure, handle variable numbers of ingredients, and learn how components interact at different concentrations. Most formulation teams do not have this expertise in-house, and acquiring it means either extensive hiring or years of internal development.
Model maintenance. A deployed model is not finished. It must be continuously retrained as new data arrives. Validation protocols must be maintained to ensure predictions remain reliable. Performance must be monitored for drift or degradation as the formulation space evolves.
Infrastructure. Secure data handling, compute resources for training and inference, and integration with laboratory workflows all require ongoing investment.
Most organizations would need years of systematic data generation before their models produced reliable predictions across the formulation space they care about.
FastFormulator has already done this foundational work. The platform is built on thousands of systematically designed formulations, with DOE structures specifically constructed to teach the model how ingredients behave individually and in combination. The models are already trained and validated on this foundation.
Companies using FastFormulator enter the loop with foundational models that already understand formulation chemistry. They are not starting with a blank slate that requires years of data generation before it becomes useful. They are building on top of an existing foundation, adding their own data to refine predictions for their specific ingredients and formulation styles.
Outcomes
Integrating deep learning into the formulation workflow produces concrete benefits that compound over time.
Better formulations. Model-guided exploration finds candidates that intuition might miss. The platform can identify non-obvious regions of composition space where target properties are achievable, expanding the range of solutions available to formulators.
Improved stability and performance. Predictions help avoid failure modes early. Rather than discovering instability late in development, teams can screen for potential problems computationally before committing to extensive testing.
Fewer failed trials. Prioritization reduces blind experimentation. When the model indicates that a formulation is unlikely to meet targets, resources can be directed elsewhere. The experiments that do get run are more likely to yield useful results.
Faster development cycles. Less time spent on dead ends means faster progress toward viable products. The reduction in wasted effort compounds across projects.
Lower cost. Fewer experiments means less wasted material, less instrument time, and less labor spent on formulations that were never going to work.
Stronger IP. Novel formulations discovered through systematic, model-guided exploration become proprietary knowledge. The platform helps find solutions that competitors relying on traditional methods would not discover.
The goal is not to replace experiments or scientists. It is to make every experiment more valuable and every scientist more effective. The platform handles the tedious work of tracking what has been tried, predicting what might work, and identifying where to look next. Scientists focus on deep, creative, and analytical work that requires human judgment.
FastFormulator's Approach
FastFormulator's platform is built to integrate directly into formulation workflows, providing the continuous learning loop described above without requiring years of foundational work.
The platform provides four foundational models that predict the physicochemical properties most critical to formulation performance:
- Virtual Viscometer: Predicts viscosity and full rheology flow curves across shear rates
- Virtual Stability Chamber: Predicts colloidal stability under specified conditions
- Virtual Tensiometer: Predicts surface tension behavior vs surfactant concentration
- Virtual Foam Analyzer: Predicts foam generation and longevity
- Other Properties: Work with us to build a custom model for a new key property of interest for your products.
These models are trained on real experimental data from systematically designed formulations. The extensive DOE-based pretraining means companies do not start from zero. From day one, the platform provides predictions grounded in thousands of prior formulation experiments.
The platform learns from your data without compromising data security. Proprietary customer data is siloed and never shared or used to train models that other customers access. Customer-specific models improve with every experiment uploaded, requiring less and less new data as understanding builds.
The result is a chemical intelligence platform that understands your formulation space and grows with your organization. It captures institutional knowledge in a form that persists, can be queried, and improves over time. It enables the continuous learning workflow that traditional approaches cannot achieve.
Takeaways
Traditional formulation workflows generate data but rarely learn from it systematically. Data sits in files, knowledge lives in individual heads, and each project largely starts fresh.
Deep learning platforms change this by becoming an integral part of the workflow cycle. The seven-stage workflow, from defining targets through designing experiments, running tests, uploading data, learning, predicting, and deciding, creates a continuous loop where every experiment contributes to an expanding foundation of insight.
As this loop continues, less data is needed to extend predictions into new regions of formulation space. The model learns transferable patterns that make future work more efficient.
Building this capability from scratch requires years of systematic data generation and specialized expertise in both formulation science and machine learning. FastFormulator provides foundational models that have already undergone this buildup, allowing companies to enter the loop with a head start rather than starting from zero.
The platform does not replace scientists or experiments. It makes both more effective by handling the pattern recognition and prediction work that computers do well, freeing formulators to focus on the creative and analytical work that requires human expertise.
References
- Holmberg, K. et al. Surfactants and Polymers in Aqueous Solution (2nd ed.). Wiley.
- Tadros, T.F. Applied Surfactants: Principles and Applications. Wiley-VCH.
- Montgomery, D.C. Design and Analysis of Experiments (10th ed.). Wiley.
- Cornell, J.A. Experiments with Mixtures: Designs, Models, and the Analysis of Mixture Data (3rd ed.). Wiley.
- Schramm, L.L. Emulsions, Foams, and Suspensions: Fundamentals and Applications. Wiley-VCH.
- Keith, J.A. et al. Combining Machine Learning and Computational Chemistry for Predictive Insights Into Chemical Systems. Chemical Reviews, 121, 9816-9872 (2021).
- Butler, K.T. et al. Machine Learning for Molecular and Materials Science. Nature, 559, 547-555 (2018).